Using resources effectively
Overview
Teaching: 10 min
Exercises: 20 minQuestions
How can I review past jobs?
How can I use this knowledge to create a more accurate submission script?
Objectives
Look up job statistics.
Make more accurate resource requests in job scripts based on data describing past performance.
We’ve touched on all the skills you need to interact with an HPC cluster: logging in over SSH, loading software modules, submitting parallel jobs, and finding the output. Let’s learn about estimating resource usage and why it might matter.
Estimating Required Resources Using the Scheduler
Although we covered requesting resources from the scheduler earlier, how do we know what type of resources the software will need in the first place, and its demand for each? In general, unless the software documentation or user testimonials provide some idea, we won’t know how much memory or compute time a program will need.
Read the Documentation
Most HPC facilities maintain documentation as a wiki, a website, or a document sent along when you register for an account. Take a look at these resources, and search for the software you plan to use: somebody might have written up guidance for getting the most out of it.
Why estimate resources accurately when you can just ask for the maximum CPUs/GPUs/RAM/time?
- The more you can fine-tune your requests, the less resources you will need to request and thus the less time your jobs will wait in the queue.
- The less your Fair Share score will be impacted.
- Less time to research results!
Will my code run faster if I use more than 1 CPU/GPU?
Only if your code can use > 1 CPU/GPU. Please read your code’s documentation! Look for the software’s flags/options for CPUs/threads/cores and match these to sbatch parameters (-c or -n)
Method 1: ssh to compute node and monitor performance with htop
This method can be done before you scale up and run your code with an sbatch script.
-
srun --pty bash -
load modules, run your code in the background
[SUNetID@wheat01:~]$ python3 mycode.py > /dev/null 2>&1 & [SUNetID@wheat01:~]$ htop -u $USER
You will see how many CPUs, threads and how much RAM your code is using in real-time by running the htop or top command on the compute node as your code runs in the background.
Note: > /dev/null 2>&1 & will redirect all code output away from the terminal and keep the command line prompt available for you to run htop/top.
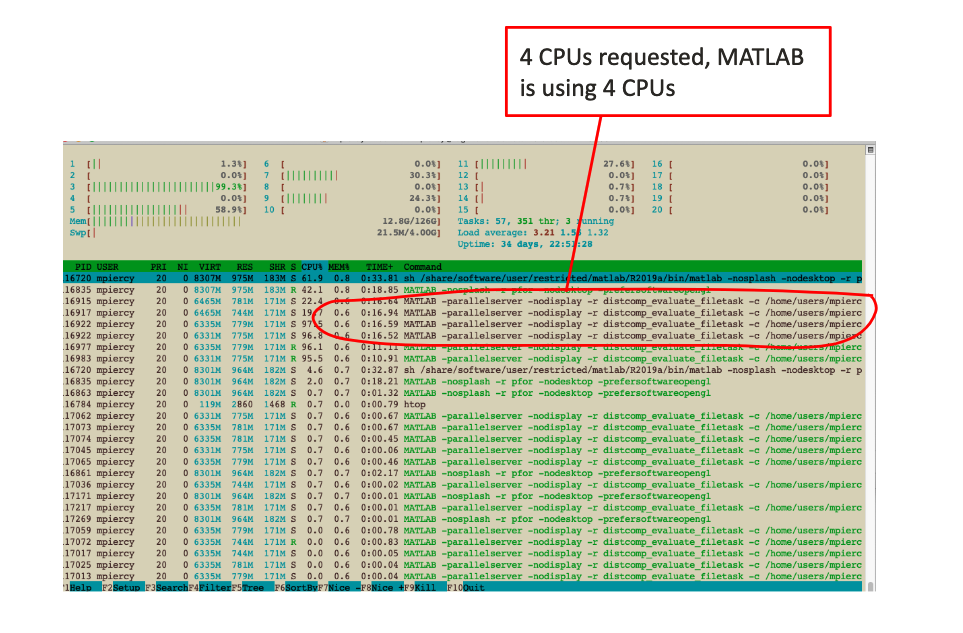
htop example on a compute node: showing all 4 requested CPUs used
[SUNetID@rice-02:~]$ srun -c 4 --pty bash
[SUNetID@wheat01:~]$ ml load matlab
[SUNetID@wheat01:~]$ matlab -batch "pfor" > /dev/null 2>&1&
[SUNetID@wheat01:~]$ htop
Method 2: Use seff to look at resource usage after a job completes
seff displays statistics related to the efficiency of resource usage by a
completed job. These are approximations based on SLURMs job sampling rate of one
sample every 5 minutes.
seff <jobid>
[SUNetID@rice-02:~]$ seff 66594168
Job ID: 66594168
Cluster: sherlock
User/Group: mpiercy/<PI_SUNETID>
State: COMPLETED (exit code 0)
Nodes: 1
Cores per node: 12
CPU Utilized: 00:02:31
CPU Efficiency: 20.97% of 00:12:00 core-walltime
Job Wall-clock time: 00:01:00
Memory Utilized: 5.79 GB
Memory Efficiency: 12.35% of 46.88 GB
-
Look at CPU Efficiency and compare to the number of CPUs you requested. For example if you requested 4 CPUs and CPU Efficiency was 20-25% you probably only needed to request 1 CPU.
-
The same estimation can be used with memory request by looking at Memory Efficiency.
Example 1: Job 43498042
[SUNetID@rice-02:~]$ seff 43498042
Job ID: 43498042
Cluster: sherlock
User/Group: mpiercy/<PI_SUNETID>
State: TIMEOUT (exit code 0)
Nodes: 1
Cores per node: 2
CPU Utilized: 00:58:51
CPU Efficiency: 96.37% of 01:01:04 core-walltime
Job Wall-clock time: 00:30:32
Memory Utilized: 3.63 GB
Memory Efficiency: 90.84% of 4.00 GB
So, this job ran on all CPUs for the entire time requested, 30 minutes.
Thus core-walltime is 2x30 minutes or 1 hour. 96.37%, pretty efficient!
Note that seff is for completed jobs only.
Example 2 (over-requested resources): Job 43507209
[SUNetID@rice-02:~]$ seff 43507209
Job ID: 43507209
Cluster: sherlock
User/Group: mpiercy/ruthm
State: TIMEOUT (exit code 0)
Nodes: 1
Cores per node: 2
CPU Utilized: 00:29:15
CPU Efficiency: 48.11% of 01:00:48 core-walltime
Job Wall-clock time: 00:30:24
Memory Utilized: 2.65 GB
Memory Efficiency: 66.17% of 4.00 GB
Because 2 CPUs were requested for 30 minutes (Job Wall-clock time) but only one was used by the code (CPU Utilized), we get a CPU Efficiency of 48.11% - basically 50%. 2 CPUs where requested for 30 minutes each, so we see 1 hour total core-walltime requested but only 30 minutes was used.
So in this case there was no logical reason to request 2 CPUs, 1 would have been sufficient.
The memory was sufficiently utilized and we did not get an out of memory error, so we probably don’t need to request any extra.
Method 3: Use sacct to look at resource usage after a job completes
We can also use sacct to estimate a job’s resource requirements. sacct provides
much more detail about our job than seff does, and we can customize the output
with the -o flag.
sacct -o reqmem,maxrss,averss,elapsed,alloccpu -j <jobid>
Let’s compare two jobs, 20292 and 426651.
[SUNetID@rice-02:~]$ sacct -o reqmem,maxrss,averss,elapsed,alloccpu -j 20292
ReqMem MaxRSS AveRSS Elapsed AllocCPUS
---------- ---------- ---------- ---------- ----------
4Gn 00:08:53 1
4Gn 3552K 5976K 00:08:57 1
4Gn 921256K 921256K 00:08:49 1
Here, the job only used .92 GB but 4 GB was requested. So, about 3 GB was needlessly
requested so the job waited in the queue longer than needed before it ran.
Note that SLURM only samples a job’s resources every few minutes, so this is an average.
Jobs with a MaxRSS close to ReqMem can still get an out of memory (OOM event) error and
die. When this happens, request more memory in your sbatch with --mem=
- ReqMem = memory that you asked from SLURM. If it has type Mn, it is per node in MB, if Mc, then it is MB per core
- MaxRSS = maximum amount of memory used at any time by any process in that job. This applies directly for serial jobs. For parallel jobs you need to multiply with the number of cores
- AveRSS = the average memory used per process (or core). To get the total memory used, multiply this with number of cores used
- Elapsed = time it took to run your job
[SUNetID@rice-02:~]$ sacct -o reqmem,maxrss,averss,elapsed,alloccpu -j 426651
ReqMem MaxRSS AveRSS Elapsed AllocCPUS
---------- ---------- ---------- ---------- ----------
4Gn 00:08:53 1
4Gn 3552K 5976K 00:08:57 1
4Gn 2921256K 2921256K 00:08:49 1
Here, the job came close to hitting the requested memory, 4 GB, 2.92 GB was used. This was a pretty accurate request.
sacct accuracy and sampling rate
sacct memory values are based on a sampling of the applications memory at a specific time.
Remember that sacct results for memory usage (MaxVMSize, AveRSS, MaxRSS) are often not accurate for Out Of Memory (OOM) jobs.
This is because the job is often terminated prior to next sacct sampling and also terminated prior to it reaching full memory allocation.
Example 1: Job 43498042
Here we will use sacct to look at resource usage for job 43498042 (the same job that
is in Example 1 of the seff section).
[SUNetID@rice-02:~]$ sacct --format=JobID,state,elapsed,MaxRss,AveRSS,MaxVMSize,TotalCPU,ReqCPUS,ReqMem -j 43498042

So, sacct shows that this job used 3.8GB of memory (MaxRSS and AveRSS) and 4GB was requested, an accurate request!
MaxVMSize, virtual memory size is usually not representative of the memory used by your application, it aggregates potential memory ranges from shared libraries, memory that has been allocated but not used, in addition to swap memory, etc. It’s usually much greater than what your job’s application actually used. MaxRSS and AveRSS are much better metrics.
There are times when a very large MaxVMSize does indeed indicate that insufficient memory was requested.
Example 2: Job 43507209
Here we will use sacct to look at resource usage for job 43507209 (the same job that
is in Example 2 of the seff section).
[SUNetID@rice-02:~]$ sacct --format=JobID,state,elapsed,MaxRss,AveRSS,MaxVMSize,TotalCPU,ReqCPUS,ReqMem -j 43507209
So MaxRSS, the maximum resident memory set size of all tasks in the job was 2.77 GB and AveRSS was also 2.77 GB. 4GB was requested so this was a pretty accurate request.
Key Points
Accurate job scripts help the queuing system efficiently allocate shared resources.